导语
目前,预训练已经成为了自然语言处理领域最常用的技术之一。我们在做一个自然语言处理任务的时候,一般会去找一个预训练模型。高质量的预训练模型能够为下游任务带来显著的提升。本文介绍一个预训练模型框架UER(Universal Encoder Representations),并介绍如何利用UER去使用基于不同语料、编码器、目标任务的中文预训练模型,从而在下游任务上取得比Google BERT更好的效果。UER的代码和模型仓库可以在这里获取到 https://git**.com/dbiir/UER-py 。用户可以根据自己的需求在模型仓库中选择适合下游任务的预训练模型进行下载并训练。
1 UER-py介绍
UER-py全称是Universal Encoder Representations,-py指这个项目用PyTorch实现。UER-py是一个在通用语料预训练以及对下游任务进行微调的工具包。我们知道预训练模型有几个关键的部分:语料、编码器、目标任务、以及微调策略。UER-py能让用户轻易的对不同的部分进行组合,复现已有的预训练模型(比如BERT),并为用户提供进一步扩展的接口。我们可以用UER-py加载不同的预训练模型,从而在各种下游任务上取得SOTA的表现。下面我们跟随UER-py的readme中的quick start,看看如何使用UER-py,帮助我们在一系列下游任务上取得比Google BERT更好的效果。
2 使用BERT做情感分类任务
首先我们以非常火的BERT模型和豆瓣书籍评论分类数据集为例来简要说明如何使用UER。我们首先在无监督书评语料上对模型进行预训练,然后在分类数据集上进行微调。我们需要提供三个输入文件:书评语料、书评分类数据集、以及词表。所有文件都以UTF-8编码。这三个文件均已经包含在这个项目中了。
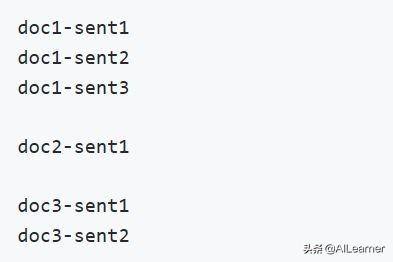
下面我们简单看一下这三个文件的格式。用于BERT预训练的语料格式如下图,一行一个句子(sentence),文档(document)之间用空行分隔:
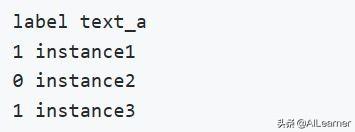
分类下游任务数据集格式如下,标签和文本之间用\t分隔:
词表格式如下,一行一个单词:

根据项目的介绍,这里使用的书评语料由书评分类数据集**,因此书评语料其实是非常小的。
下面就开始使用UER将BERT模型用于书评分类!根据readme的提升,首先我们要下载预训练模型。我下载了一个Google官方的预训练模型 https://share.weiyun.com/5s9A**Q 。把其放到models文件夹中。这个文件夹存放和模型有关的文件,包括预训练模型,模型配置,词表等。我这里执行如下命令:
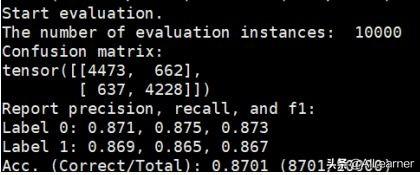
python3 classifier.py --pretrained_model_path models/google_model.bin --vocab_path models/google_vocab.txt --train_path datasets/book_review/train.tsv --dev_path datasets/book_review/dev.tsv --test_path datasets/book_review/test.tsv --epochs_num 3 --batch_size 32 --encoder bertpretrained_model_path用于指定预训练模型的路径;vocab_path用于指定词表;encoder用于指定使用的编码器,注意到UER除了BERT的12层Tran**ormer之外,还包括了大量其它的编码器。我这里跑出的结果是87.01,和readme中说的87.5差距并不大。
下面,我们在语料上进行预训练,然后将我们预训练的模型用于下游任务,看看能不能比Google提供的模型有进一步的提升(期待!)。
要进行预训练需要执行两个程序:
第一步:运行preprocess.py,输入是语料,生成dataset.pt文件。这个步骤将语料的文字处理成预训练模型能接收的格式。多**能大大加速预处理过程,同时预处理还需要指定预训练的目标任务,因为不同的目标任务有着不同的格式:
python3 preprocess.py --corpus_path corpora/book_review_bert.txt --vocab_path models/google_vocab.txt --dataset_path dataset.pt --processes_num 8 --target bert第二步:运行pretrain.py,输入是dataset.pt文件。生成book_review_model.bin。readme中使用8个GPU进行预训练,但是我只有一个GPU!!因此我的执行命令如下:
python pretrain.py --dataset_path dataset.pt --vocab_path models/google_vocab.txt --pretrained_model_path models/google_model.bin --output_model_path models/book_review_model.bin --world_size 1 --gpu_ranks 0 --total_steps 2000 --save_checkpoint_steps 500 --encoder bert --target bert --batch_size 16Readme中默认的是batch_size是32,但是我的显存支持不了这么大,因此设置成16。由于计算资源非常有限,这步我没有执行完,直接下载了UER给的已经训练好的模型,并用于下游任务之上:
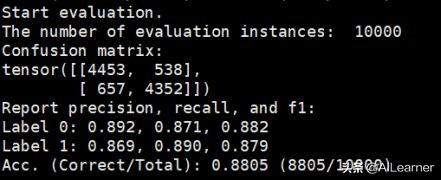
python3 classifier.py --pretrained_model_path models/book_review_model.bin --vocab_path models/google_vocab.txt --train_path datasets/book_review/train.tsv --dev_path datasets/book_review/dev.tsv --test_path datasets/book_review/test.tsv --epochs_num 3 --batch_size 32 --encoder bert和之前的命令相比,只是pretrained_model_path换了一下。最后的结果到了88.05!相对于Google BERT提升还是挺明显的。
后面,我继续下载了一个使用分类作为目标任务的预训练模型——amazon_cls_model.bin,效果又好了不少。虽然BERT的效果已经非常厉害了,但是还是有不少的提升空间。
3 使用轻量级编码器做情感分类任务
BERT用了12层Tran**ormer编码器,真的是太慢了。跟着UER的Readme的quick start,我尝试了一个轻量级的编码器,两层LSTM。这里希望2层LSTM编码器来代替12层Tran**ormer编码器,以期实现更为快速的训练过程,同时能够兼顾准确率。这里我下载了readme推荐的用语言模型和分类目标任务预训练的LSTM编码器。lstm_reviews_model.bin是通过在大规模复合语料上进行语言模型,以及在亚马逊书评语料上做语言模型+分类任务**的预训练模型。之后我们将这个预训练模型用于豆瓣书评数据集和百度ChnSentiCorp数据集的情感分类任务,亚马逊书评语料与上述两个下游任务数据集没有任何关联,不需要担心信息泄露。
将LSTM编码器用于豆瓣书评分类任务:
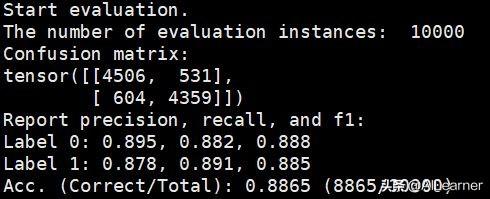
python3 classifier.py --pretrained_model_path models/lstm_reviews_midel.bin--vocab_path models/google_vocab.txt--train_path datasets/book_review/train.tsv --dev_path datasets/book_review/dev.tsv --test_path datasets/book_review/test.tsv--epochs_num 3 --batch_size 64 --encoder lstm --pooling mean --config_path models/rnn_config.json--learning_rate 1e-3使用轻量级编码器的分类任务可以在测试集上达到86.68的准确度,这同样是一个有竞争力的结果。因为使用没有预训练过的LSTM只能达到80.2的准确度,而且在实验中,上述模型比BERT快约10倍,但是只比使用Google BERT预训练模型(准确度为87.01)差了0.33。
将LSTM编码器用于百度ChnSentiCorp情感分类任务:
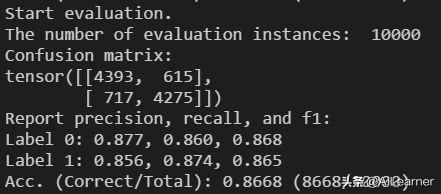
python3 classifier.py --pretrained_model_path models/lstm_reviews_model.bin--vocab_path models/google_vocab.txt--train_path datasets/ChnSentiCorp/train.tsv --dev_path datasets/ChnSentiCorp/dev.tsv --test_path datasets/ChnSentiCorp/test.tsv--epochs_num 3 --batch_size 64 --encoder lstm --pooling mean --config_path models/rnn_config.json--learning_rate 1e-3实验结果在测试集上可以达到94.5的准确度,BERT在该数据集上的结果有94.3的准确度,将轻量级编码器用于情感分类任务,真的做到了又快又好,期待能在更多的下游任务上有好的表现!
4 使用BERT做序列标注任务
跟着readme,我最后进行了一个标注任务,数据集为MSRA-NER。这里有两个实验。第一个用Google提供的BERT预训练模型做序列标注,第二个用UER提供的在**上的BERT预训练模型做序列标注。执行脚本如下,这两个脚本的唯一区别就是pretrained_model_path不一样:
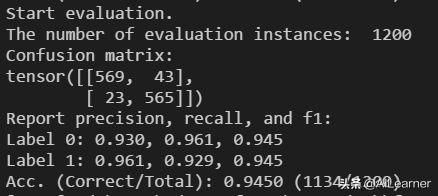
python3 tagger.py --pretrained_model_path models/google_model.bin --vocab_path models/google_vocab.txt --train_path datasets/msra/train.tsv --dev_path datasets/msra/dev.tsv --test_path datasets/msra/test.tsv --epochs_num 5 --batch_size 8 --encoder bertpython3 tagger.py --pretrained_model_path models/rmrb_model.bin --vocab_path models/google_vocab.txt --train_path datasets/msra/train.tsv --dev_path datasets/msra/dev.tsv --test_path datasets/msra/test.tsv --epochs_num 5 --batch_size 8 --encoder bert由于显存不够用,我将batch size改成了8。最后实验结果显示使用**模型的效果比Google BERT要好得多!我跑的Google BERT的结果是F值92.9:
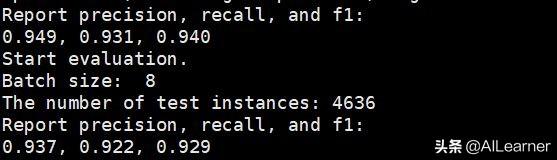
**的结果到了94.5:
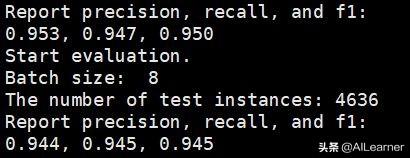
这里使用的MSRA-NER数据集和百度ERNIE提供的数据集是一模一样的。百度ERNIE的结果是93.8,可以看到这里的预训练模型相对于百度的预训练模型也有一定的优势。