机器之心报道
编辑:张倩
这篇近百页的综述梳理了预训练基础模型的演变史,让我们看到 ChatGPT 是怎么一步一步走向成功的。
所有的成功都有迹可循,ChatGPT 也不例外。
前不久,因为对 ChatGPT 的评价过于苛刻,图灵奖得主 Yann LeCun 被送上了热搜。
在他看来,「就底层技术而言,ChatGPT 并没有什么特别的创新,」也不是「什么**性的东西」。许多研究实验室正在使用同样的技术,开展同样的工作。更重要的是,ChatGPT 及其背后的 GPT-3 在很多方面都是由多方多年来**的多种技术组成的,是不同的人数十年贡献的结果。因此,LeCun 认为,与其说 ChatGPT 是一个科学突破,不如说它是一个像样的工程实例。

「ChatGPT 是否具有**性」是个充满争议的话题。但毋庸置疑,它确实是在此前积累的多项技术的基础上构建起来的,比如核心的 Tran**ormer 是谷歌在几年前提出来的,而 Tran**ormer 又受到了 Bengio 关于注意力概念的工作的启发。如果再往前追溯,我们还能链接到更古早的几十年前的研究。
当然,公众可能体会不到这种循序渐进的感觉,毕竟不是谁都会一篇一篇去看论文。但对于技术人员来说,了解这些技术的演进过程还是非常有帮助的。
在最近的一篇综述文章中,来自密歇根州立大学、北京****大学、理海大学等机构的研究者仔细梳理了该领域的几百篇论文,主要聚焦文本、图像和图学习领域的预训练基础模型,非常值得一读。杜克大学教授、加拿大工程院院士裴健,伊利诺大学芝加哥分校计算机科学系特聘教授俞士纶(Philip S. Yu),Sale**orce AI Research 副总裁熊蔡明都是该论文作者之一。

论文链接:https://arxiv.org/pdf/2302.09419.pdf
论文目录如下:


在海外社交平台上,DAIR.AI 联合创始人Elvis S.推荐了这篇综述并**了一千多的点赞量。
引言
预训练基础模型(PFM)是大数据时代人工智能的重要组成部分。「基础模型」的名字来源于 Percy Liang、李飞飞等人发布的一篇综述 ——《On the Opportunities and Risks of Foundation Models》,是一类模型及其功能的总称。在 NLP、CV 和图学习领域,PFM 已经**了广泛研究。在各种学习任务中,它们表现出了强大的特征表示学习潜力,如文本分类、文本生成、图像分类、目标检测和图分类等任务。无论是用大型数据集在多个任务上训练,还是在小规模任务上进行微调,PFM 都表现出了优越的性能,这使其快速启动数据处理成为可能。
PFM 和预训练
PFM 基于预训练技术,其目的是利用大量的数据和任务来训练一个通用模型,该模型可以在不同的下游应用中很容易地进行微调。
预训练的想法起源于 CV 任务中的迁移学习。但看到该技术在 CV 领域的有效性后,人们也开始利用该技术提高其他领域的模型性能。
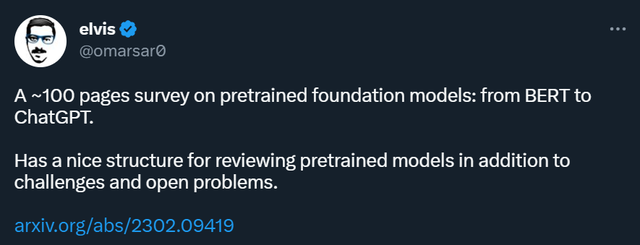
当预训练技术应用于 NLP 领域时,经过良好训练的语言模型可以捕捉到对下游任务有益的丰富知识,如**依赖关系、层次关系等。此外,预训练在 NLP 领域的显著优势是,训练数据可以来自任何未标记的文本语料库,也就是说,几乎存在着无**的训练数据可以用于预训练过程。早期的预训练是一种静态技术,如 NNLM 和 Word2vec,但静态方法很难适应不同的语义**。因此,人们提出了动态预训练技术,如 BERT、XLNet 等。图 1 描述了 PFM 在 NLP、CV 和 GL 领域的历史和演变。基于预训练技术的 PFM 使用大型语料库来学习通用语义表征。随着这些开创性工作的引入,各种 PFM 已经出现,并被应用于下游的任务和应用。
最近走红的 ChatGPT 是 PFM 应用的典型案例。它是从生成性预训练 tran**ormer 模型 GPT-3.5 中微调出来的,该模型利用了大量本文和代码进行训练。此外,ChatGPT 还应用了来自人类反馈的强化学习(RLHF),这已经成为让大型 LM 与人类意图**一致的一种有希望的方式。ChatGPT 卓越的性能表现可能会给每种类型的 PFM 的训练范式带来转变,比如指令对齐技术、强化学习、prompt tuning 和思维链的应用,从而走向通用人工智能。
本文将重点放在文本、图像和图领域的 PFM,这是一个相对成熟的研究分类方法。对于文本来说,它是一个多用途的 LM,用于预测序列中的下一个单词或字符。例如,PFM 可用于机器翻译、问答系统、主题建模、情感**等。对于图像,它类似于文本上的 PFM,使用巨大的数据集来训练一个适合许多 CV 任务的大模型。对于图来说,类似的预训练思路也被用于** PFM,这些 PFM 被用于许多下游任务。除了针对特定数据域的 PFM,本文还回顾并阐述了其他一些先进的 PFM,如针对**、视频和跨域数据的 PFM,以及多模态 PFM。此外,一场能够处理多模态任务的的 PFM 的大融合正在出现,这就是所谓的 unified PFM。作者首先定义了 unified PFM 的概念,然后回顾了最近研究中达到 SOTA 的 unified PFM(如 OFA、UNIFIED-IO、FLAVA、BEiT-3 等)。
根据上述三个领域现有的 PFM 的特点,作者得出结论,PFM 有以下两大优势。首先,要想提高在下游任务中的性能,模型只需要进行很小的微调。其次,PFM 已经在质量方面**了审查。我们可以将 PFM 应用于任务相关的数据集,而不是从头开始构建模型来解决类似的问题。PFM 的广阔前景激发了大量的相关工作来关注模型的效率、安全性和压缩等问题。
论文贡献与结构
在这篇文章发布之前,已经有几篇综述回顾了一些特定领域的预训练模型,如文本生成、视觉 tran**ormer、目标检测。
《On the Opportunities and Risks of Foundation Models》总结了基础模型的机会和风险。然而,现有的工作并没有实现对不同领域(如 CV、NLP、GL、Speech、Video)PFM 在不同方面的全面回顾,如预训练任务、效率、效力和隐私。在这篇综述中,作者详细阐述了 PFM 在 NLP 领域的演变,以及预训练如何迁移到 CV 和 GL 领域并被采用。
与其他综述相比,本文没有对所有三个领域的现有 PFM 进行全面的介绍和**。与对先前预训练模型的回顾不同,作者总结了现有的模型,从**模型到 PFM,以及三个领域的最新工作。**模型强调的是静态特征学习。动态 PFM 对结构进行了介绍,这是主流的研究。
作者进一步介绍了 PFM 的一些其他研究,包括其他先进和统一的 PFM、模型的效率和压缩、安全以及隐私。最后,作者总结了未来的研究挑战和不同领域的开放问题。他们还在附录 F 和 G 中全面介绍了相关的评价指标和数据集。
总之,本文的主要贡献如下:
对 PFM 在 NLP、CV 和 GL 中的**进行了详实和最新的回顾。在回顾中,作者讨论并提供了关于这三个主要应用领域中通用 PFM 的设计和预训练方法的见解;
总结了 PFM 在其他多媒体领域的**,如**和视频。此外,作者还讨论了关于 PFM 的前沿话题,包括统一的 PFM、模型效率和压缩,以及安全和隐私。
通过对各种模式的 PFM 在不同任务中的回顾,作者讨论了大数据时代超大型模型未来研究的主要挑战和机遇,这指导了新一代基于 PFM 的协作和互动智能。
各个章节的主要内容如下:
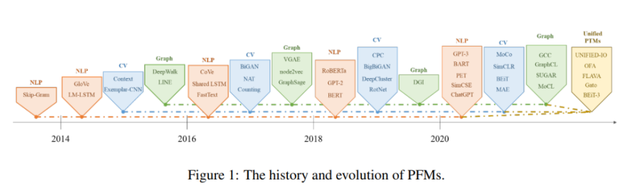
论文第 2 章介绍了 PFM 的一般概念架构。
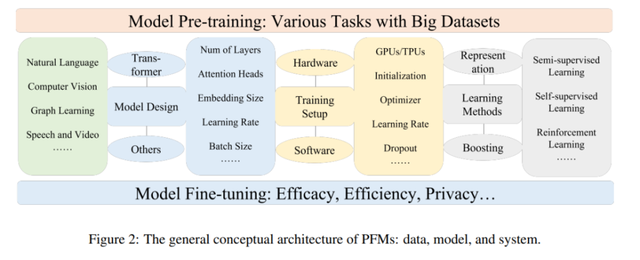
第 3、4、5 章分别总结了 NLP、CV 和 GL 领域中现有的 PFM。
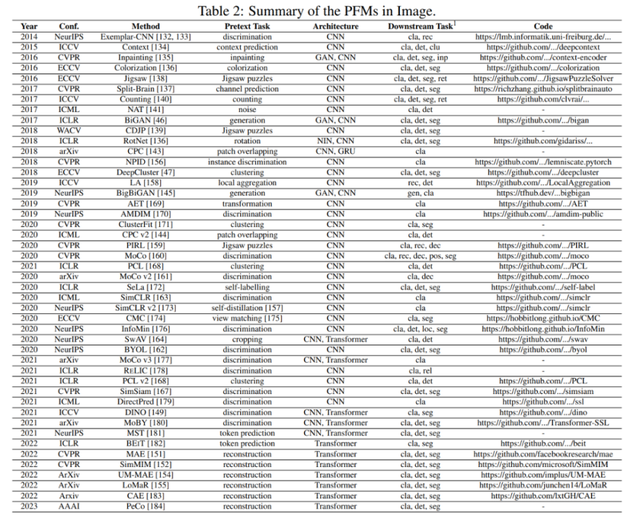
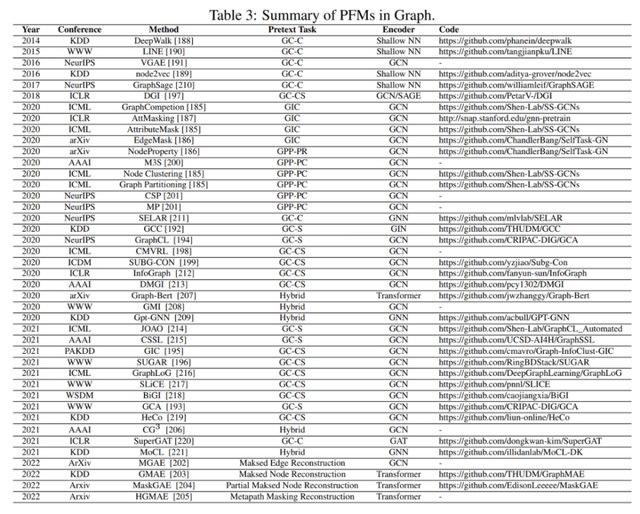
第 6、7 章介绍了 PFM 的其他前沿研究,包括前沿和统一的 PFM、模型效率和压缩,以及安全和隐私。
第 8 章总结了 PFM 的主要挑战。第 9 章对全文进行了总结。