《BERT: Pre-training of Deep Bidirectional Tran**ormers for Language Understanding》
《Attention is all you need》
Bert的Base model参数大小是110M,Large modle 是340M
 Base model
Base model(1)第一:词向量参数(embedding)
class BertEmbeddings(nn.Module): """Construct the embeddings from word, position and token_type embeddings. """ def __init__(self, config): super(BertEmbeddings, self).__init__() self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size) self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size) self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)从代码中,可以看到,词向量包括三个部分的编码:词向量参数,位置向量参数,句子类型参数(bert用了2个句子,为0和1)并且,Bert采用的vocab_size=30522,hidden_size=768,max_position_embeddings=512,token_type_embeddings=2。这就很显然了,embedding参数 = (30522+512 + 2)* 768
(2)第二:multi-heads参数(Multi-Heads Attention)这个直接看《Attention is all you need》中的Tran**ormer结构就知道了
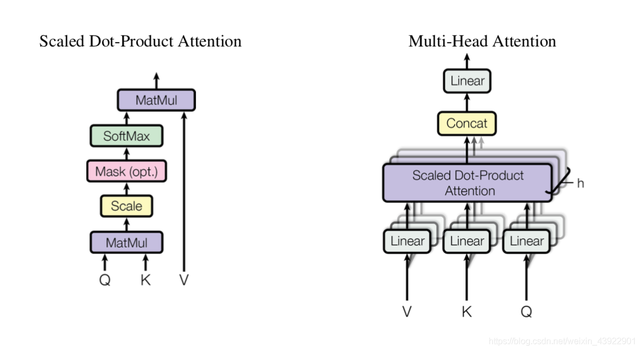
从结构中可以看到,Q,K,V就是我们输入的三个句子词向量,从之前的词向量**可知,输出向量大小从len -> len x hidden_size,即len x 768。如果是self-attention,Q=K=V,如果是普通的attention,Q !=K=V。但是,不管用的是self-attention还是普通的attention,参数计算并不影响。因为在输入单头head时,对QKV的向量均进行了不同的线性变换,引入了三个参数,W1,W2,W3。其维度均为:768 x 64。为什么是64呢,从下图可知,
Wi 的维度 :dmodel x dk | dv | dq
而:dk | dv | dq = dmodle/h,h是头的数量,dmodel模型的大小,即h=12,dmodle=768;
所以:dk | dv | dq=768/12=64
得出:W1,W2,W3的维度为768 x 64

那么单head的参数:768 * 768/12 * 3
而头的数量为h=12
multi-heads的参数:768 * 768/12 * 3 * 12
之后将12个头concat后又进行了线性变换,用到了参数Wo,大小为768 * 768
那么最后multi-heads的参数:768 * 768/12 * 3 * 12 + 768 * 768
(3)全连接层(FeedForward)参数
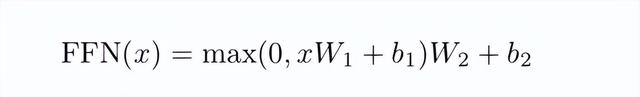
以上是论文中全连接层的公式,其中用到了两个参数W1和W2,Bert沿用了惯用的全连接层大小设置,即4 * dmodle,为3072,因此,W1,W2大小为768 * 3072,2个为 2 * 768 * 3072。
(4) LayerNorm层文章其实并没有写出layernorm层的参数,但是在代码中有,分别为gamma和beta。在三个地方用到了layernorm层:①词向量处
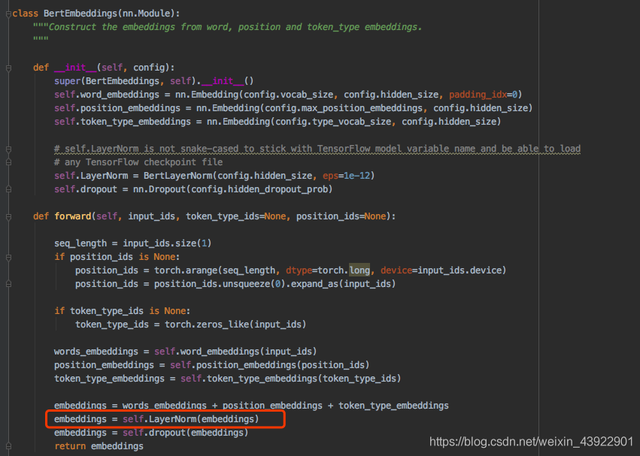
②多头注意力之后
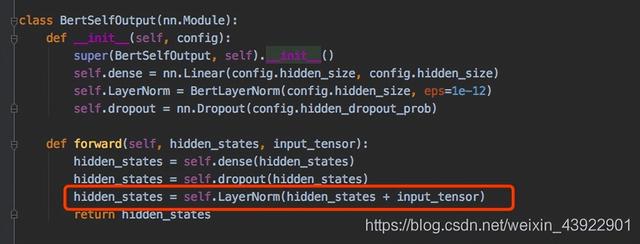
③最后的全连接层之后
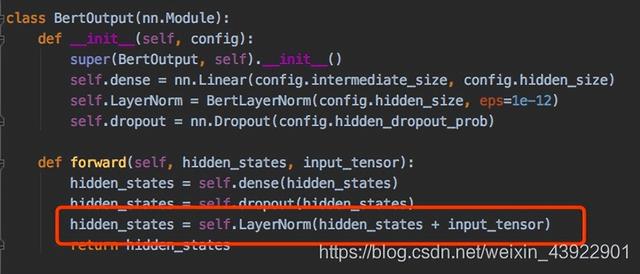
但是参数都很少,gamma和beta的维度均为768。因此总参数为768 * 2 + 768 * 2 * 2 * 12(层数)
而Base Bert的encoder用了12层,因此,最后的参数大小为:
词向量参数(包括layernorm) + 12 * (Multi-Heads参数 + 全连接层参数 + layernorm参数)= (30522+512 + 2)* 768 + 768 * 2 + 12 * (768 * 768 / 12 * 3 * 12 + 768 * 768 + 768 * 3072 * 2 + 768 * 2 * 2) = 108808704.0 ≈ 110M
PS:本文介绍的参数仅仅是encoder的参数,基于encoder的两个任务next sentence prediction 和 MLM涉及的参数(768 * 2,2 * 768 * 768,总共约1.18M)并未加入,此外涉及的bias由于参数很少,本文也并未加入。