在 33 亿文本的语料上训练,根据不同的任务进行微调,最终实现 11 项 NLP 任务的突破进展。这就是谷歌于 2018 年 8 月发布的 NLP 模型——BERT。
因其强大的预训练效果,BERT 诞生之后便受到学术界、工业界热捧,甚至一度被称为是“地表最强 NLP 模型“。
但是,这个 NLP 模型的光环却笼罩在训练耗时的阴影之下:BERT 的预训练需要很长时间才能完成,在 16 个 TPUv3 芯片上大约需要三天,对应的计算资源消耗也会比较多。因此,BERT 被调侃为一项“大力出奇迹”的成果。
一直有不同的 AI 研究团队尝试缩短其训练时间,也都取得了相应的进展。例如,在今年年初,谷歌的研究团队就曾提出新的优化器——LAMB 优化器,将训练的 batch size 推到硬件的极限,使用 TPU Pod ( 1024 块 TPUv3 芯片),成功将BERT的训练时长从 3 天又缩短到了 76 分钟。
现在,这个数字又被打破。在一场面向媒体的会议上,英伟达宣布,使用 DGX SuperPOD 深度学习服务器加之 Tensor RT 5.0 的优化,BERT模型最快只需 53 分钟就能在GPU上完成训练。据悉,DGX SuperPOD 的运算能力能达到每秒进行 9.4 千万亿次浮点运算。
对于 NLP 领域来说,这意味着又一个新的开始,BERT 等突破性大型 NLP 模型的训练时长仍有压缩空间。尤其是在工业应用上,训练时长的缩短可以直接带来成本上的节约,BERT 等突破性模型在规模化应用上又**了一大阻力。

(来源:英伟达)
英伟达深度学习应用研究副总裁 Bryan Catanzaro 对 DeepTech 介绍道,除了 53 分钟的训练时长突破以外,BERT 的推理时耗也缩短到了 2.2 毫秒(10 毫秒被认为是业内的高水位),完成 83 亿参数的最大模型训练。英伟达认为,以上三点突破,也将推动实时对话式 AI( Real-Time Conversational AI)的**。
现在,英伟达将公开 BERT 训练代码和经过 TensorRT 优化的 BERT 样本,所有人都可以通过 GitHub 利用。
(来源:英伟达)
Bryan Catanzaro 称,与简单的交易场景下的 AI 不同,对话式 AI 更关注对话而非交易,为了保证用户体验需要提供即时的响应,因此对话式 AI 的模型会越来越大,且实时性更强。
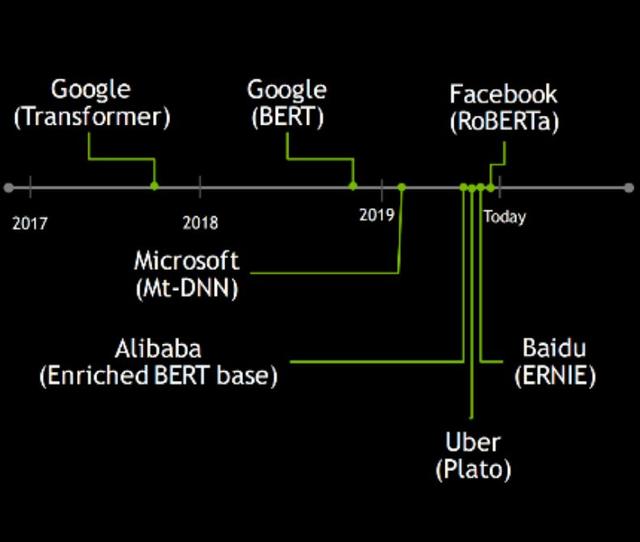
目前,国外以 FaceBook、谷歌、微软为首,国内以百度、阿里巴巴为首,**全球互联网几大最主要流量入口的科技公司、都在对话式AI领域竞相追逐,以期能够在新一代的互联网交互式体验上独领**。
2017 年至今,这几家公司也引领了对话式 AI 研究的几个重要成果:2017 年年底,谷歌的 Tan**omer 问世,开启了新的范式,随后是 2018 年底的谷歌 BERT;2019 年的对话式 AI 的研究更是百花齐放,微软 Mt-dnn、阿里巴巴的E nriched BERT base,Uber 的 Plato,百度的 ERNIE,以及近期 Facebook 推出的 RoBERTa,都是值得关注的研究。
(来源:英伟达)
英伟达表示,这些公司中已经有使用其 AI 技术进行对话式 AI 的研究,例如微软必应。微软必应正在通过其 Azure AI 平台和英伟达技术的强大功能来推动更准确的搜索结果。
微软必应团队项目经理 Rangan Majumder 称,“通过与英伟达的密切合作,必应使用 GPU(Azure AI基础架构的一部分)优化了BERT的推理,这让必应去年的搜索质量排名大幅提升。与基于 CPU 的平台相比,我们使用 Azure NVIDIA gpu进行推理时,延迟**了两倍,吞吐量提高了五倍,使必应能够为全球所有客户提供更相关、更划算、更实时的搜索体验。”
对话式 AI 近几年才显现出其商业价值,英伟达希望在这个正处于成**的市场扮演计算服务提供商的角色。